6.2. Annotation in INCEpTION
In diesem Guide wird im Detail erklärt, wie ein Dokument in Inception annotiert werden sollte, damit es durch das BeNASch-assoziierte Postprocessing korrekt verarbeitet werden kann. Die hier empfohlene Methode der Annotation zielt darauf ab, möglichst weniger “überflüssige” Tags setzen zu müssen.
Es wird angenommen, dass ein Projekt nach den Empfehlungen in Kapitel 7.1. aufgesetzt wurde und die entsprechenden Layer “Span” und “Relation” vorhanden sind.
Entitäten annotieren
Textspanne markieren
{: .note } Wir empfehlen, das “Span”-Layer auf Token-basierte Annotation zu setzen. Dies ermöglicht etwas schnelleres Markieren der Textspannen, weil nicht exakt die Endungen der Wörter markiert werden müssen. Durch Doppelklick kann ein Token schnell angewählt und annotiert werden.
Im Schema wurde es zwar schon erwähnt, aber wir annotieren in diesem Schema immer “lange” Spannen. Das entspricht üblicherweise den Grenzen der jeweiligen [Nominalphrase]. Es sollte ausserdem nicht vergessen, den Kopf (HEAD) zu markieren und zu annotieren (jede Entitätenerwähnung, egal ob Referenz oder Attribut, muss genau einen HEAD aufweisen!).
Label setzen
Um den Annotationsprozess zu beschleunigen, verzichtet das Projekt darauf, für jede Klassifikation von Entitäten mehrere Felder zu verwenden. Stattdessen werden alle Informationen unter dem Feature “Label” verzeichnet. Die verwendeten Abkürzungen entsprechen übrigens denen, die im Schema jeweils in Klammern stehen.
Für Referenzen folgt diese Annotation dem folgenden Schema:
- Erwähnungs-Klassifikation
- Entitäts-Klassifikation
- Optional: Erwähnungs-Präzisierung
- Optional: Ordinalität
- Optional: Spezifität
z.B.: “Hans Peter” → NAM.PER
z.B.: “das Haus” → NOM.LOC
z.B.: “der Schneider” → NOM.PER.OCC
z.B.: “ihnen” → PRO.PER.GRP
Attribute markieren wir durch ein “att”, dieses impliziert zudem eine Entitäts-Klassifikation als NOM. Die Entitäts-Klassifikation, Ordinalität und Spezifität werden ebenfalls vom “Mutter”-Element geerbt und müssen daher nicht explizit annotiert werden. Danach können die übrigen optionalen Klassifikationen folgen:
- Optional: Erwähnungs-Präzisierung
- Optional: PRO oder NAM falls es sich nicht um ein NOM handelt
z.B.: “Hans Peter, [der Schneider]” → ATT.OCC
z.B.: “die Herren, [denen Hans Peter noch schuldig ist]” → ATT.CREDITOR.PRO
Die optionalen Klassifikationen müssen nur annotiert werden, wenn sie vom Standard-Wert abweichen. Standard-Werte gelten wie folgt: | Klassifikation | Standard-Wert | | ———– | ———– | | Erwähnungs-Präzisierung | Leer | | Ordinalität | Singular (SGL) | | Spezifität | Spezifisch (SPC) |
{: .note } Im Postprocessing können die Standard-Werte in “schema_info.json” angepasst werden.
Pronomina können sogar noch weiter verkürzt werden, solange sie eine Koreferenz zu einem Label aufweisen, welches die vollen Informationen aufweist. Ein PRO reicht in dem Fall aus.
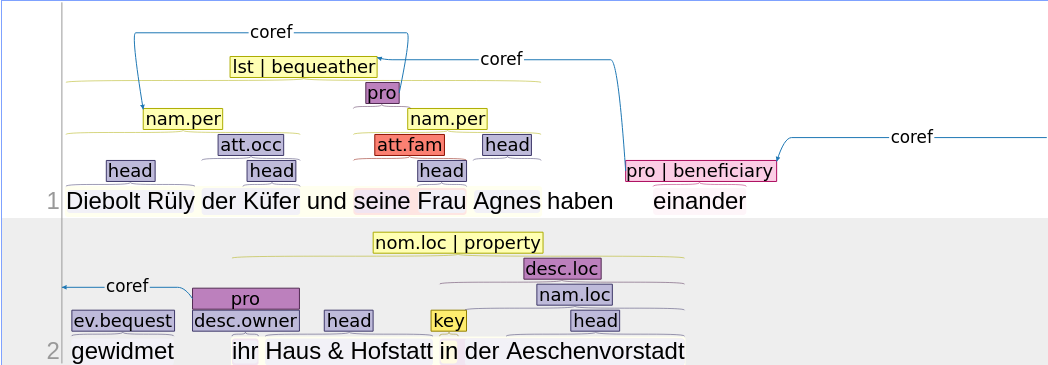
Beispiel
Ein Dokument könnte nach diesem Schritt folgendermassen aussehen:
Deskriptoren annotieren
Textspanne markieren
Auch Deskriptoren sollten der Syntax des Satzes folgen. Es sollte nicht vergessen werden, dass auch Pronomina Entitätenerwähnungen darstellen, und daher nicht als Deskriptoren, sondern als Attribute zu annotieren sind.
Das Setzen eines “Key” ist in der derzeitigen BeNASch-Version nicht obligatorisch.
Label setzen
Die Auswahl an möglichen Deskriptoren ist gross, da sie auch alle Typen von Relationen und Ereignissen abdeckt. Deskriptoren werden mit “desc” eingeleitet, danach folgt der Typus des Deskriptors.
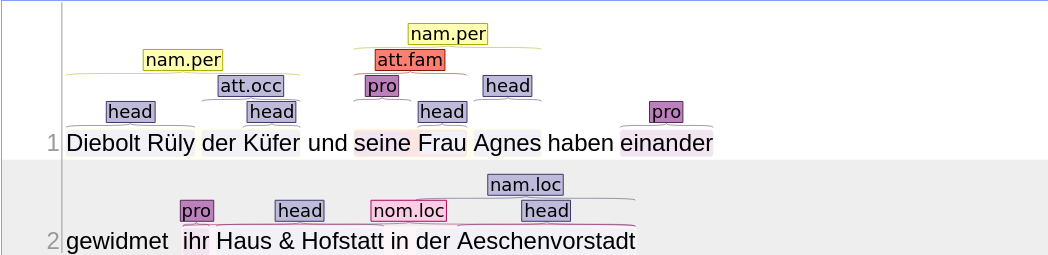
Beispiel
Ein Dokument könnte nach diesem Schritt folgendermassen aussehen:
Relationen annotieren
Zur Erinnerung
Eine Relation besteht immer aus zwei Entitätenerwähnungen und einem Typus.
Relationen und Koreferenzen per Linie setzen
Wir können Relationen, insbesondere wenn sie nicht in einer verschachtelten Erwähnung stattfindet, durch eine Linie zwischen zwei Erwähnungen darstellen. Dazu ziehen wir einfach mit gedrückter linker Maustaste den Pfeil von der einen Erwähnung zu der anderen Erwähnung und schreiben den Typus in das Feld “Label” (Kein rel. oder so notwendig).
Relationen in Attributen und Deskriptoren
Findet die Beziehung innerhalb einer verschachtelten Erwähnung statt, wird sie entweder durch ein Attribut oder einen Deskriptor repräsentiert.
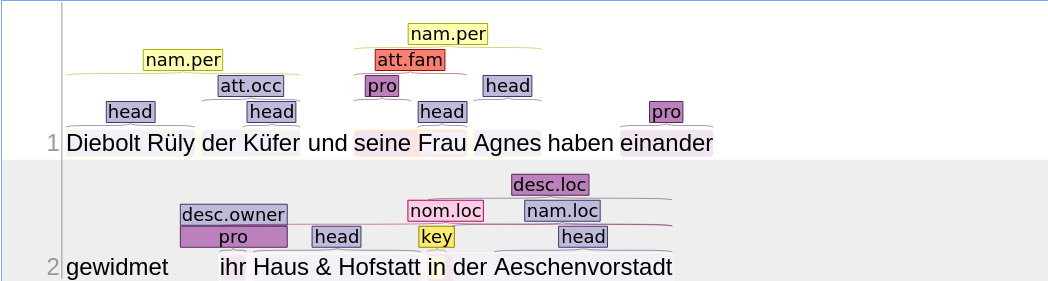
Im Beispiel unten z.B. sehen wir die Beziehung vom Typus FAM im Attribut “seine Frau” enthalten. Das Postprocessing produziert daraus die Beziehung “seine Frau” hat Beziehung FAM mit “seine“. Also: das Postprocessing erzeugt eine beliebige Anzahl Beziehungen mit dem gleichen Typus wie dem des Attributs, welche das Attribut selbst mit allen Entitätenerwähnungen, die im Attribut stehen, verbinden.
Die Wiedergabe durch Deskriptoren funktioniert ähnlich. Nur wird in diesem Fall die Entität, welche durch den Deskriptor beschrieben wird, mit der (oder den Entitäten), die innerhalb des Deskriptors stehen, verbunden. Im Beispiel unten wird also das “Haus & Hof” mit der “Aeschenvorstadt” durch eine Beziehung des Typus “loc” im Postprocessing generiert.
Gerichtete Beziehungen
Viele Beziehungen sind gerichtet (siehe Beziehungstypologie in Kapitel 4). Wird die Beziehung per Pfeil gesetzt, sollte die Beziehung in Richtung Pfeil gelesen werden. z.B. “Hans arbeitet beim Spital”. Ist die Beziehung verschachtelt gilt die Richtung von der äusseren Spanne zur inneren Spanne (z.B. “[Hans, [Schaffner des [Spitals]]]” => Hans arbeitet beim Spital). Noch besser ist es, bei gerichteten Beziehungen die Rollen direkt zu benutzen, z.B. bei einem Schuldverhältnis “Creditor” und “Debitor”.
Beispiel
Ein Dokument könnte nach diesem Schritt folgendermassen aussehen:
Ereignisse annotieren
Zur Erinnerung
Ein Ereignis besteht aus einer Ereignis-Spanne, welche einer bestimmten syntaktischen Einheit entspricht, einem Ereignis-Trigger und einer vom Ereignis abhängigen Anzahl von assoziierten Rollen.
Grundlegendes
Die Ereignis-Spanne wird im “Label”-Feature mit dem Präfix “evspan” gekennzeichnet. Darauf folgt der Ereignis-Typus. Die Ereignis-Spanne kann weggelassen werden (wie im Beispiel unten), dann setzt das Postprocessing die Spanne automatisch von der ersten Rolle/Trigger bis zur letzten Rolle/Trigger im Text.
Der Trigger wird wie eine Entität oder Deskriptor gesetzt und im “Label”-Feature mit dem Präfix “ev” markiert. Ein Ereignis kann in seltenen Fällen ohne Trigger auftreten. Dann ist es wichtig den Ereignis-Typus zumindest in der Ereignis-Spanne festzuhalten.
Für Rollen verwenden wir das “Role”-Feature. Dort wird die Role einfach eingeschrieben. Auch Ereignis-Spannen und/oder Trigger können eine Rolle in einem anderen Ereignis erhalten.
Mehrere Ereignisse im selben Satz
Angenommen die Satzebene ist eure Annotationsebene (ansonsten ersetze hier “Satz” durch eure Annotationsebene, z.B. “Kapitel” oder “Dokument”), und mehrere Ereignisse kommen darin vor, müssen wir die Rollen und Trigger voneinander trennen. Wir verwenden dazu eine Nummerierung. Aus “evspan” wird “evspan1”, aus “ev” “ev0”, aus “role” “role.0”. Im seltenen Fall, dass mehr als 10 Ereignisse in einer Ebene vorkommen, muss ein weiterer Punkt hinter die Zahl gesetzt werden, zumindest bei den Rollen (z.B. “role.21.”).
Findet ein weiteres Ereignis in einer anderen, tieferen Annotationsebene, z.B. in einem Deskriptor einer Entitätenerwähnung, statt, kann sie ohne Nummerierung vom anderen Ereignis unterschieden werden.
Unter-Ereignisse
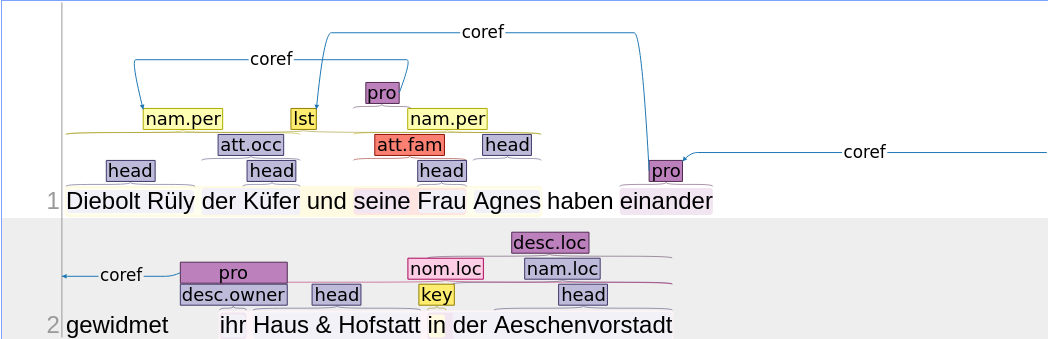
Unter-Ereignisse zeichnen sich dadurch aus, dass sie miteinander dieselbe Ereignis-Spanne und denselben Trigger teilen. Auch für Unterereignisse verwenden wir eine numerische Identifikation. Am einfachsten demonstrieren wir dies an einem Beispiel:

Hier entstehen die folgenden (Unter-)Ereignisse:
100: Jährlicher Zins von Eigenschaft wegen an St. Peter & St. Paulus Pfründ von 30 Sh.
101: Zins zur Weisung an St. Peter & St. Paulus Pfründ von 1 Ring Brot.
102: Zins zu Ehrschatz an St. Peter & St. Paulus Pfründ von 5 Sh.
110: Zins an Sopp Schenken von 1 Gulden.
120: Zins an St. Martin von 2 Gulden.
130: Zins an Christiana Herbsterin von 5 Pfund.
Ereignisse in Deskriptoren und Attributen
Wie Relationen können auch Ereignisse durch Deskriptoren und Attribute repräsentiert werden, wodurch wir uns etwas Annotation sparen können. Hierbei gilt: Ist kein Trigger annotiert, wird der Key des Deskriptors bzw. der Head des Attributs vom Postprocessing als Trigger angenommen. In einer Setting-Datei (noch nicht implementiert) wird zudem weiteres automatisiertes Verhalten definiert, z.B. deutet ein Deskriptor vom Typus “due” nicht nur die Beschreibung des Zinsverhältnis innerhalb einer Hausbeschreibung an, sondern auch, dass das Haus die Rolle “property” im Ereignis erhält.
Ereignisse, die durch Deskriptoren oder Attribute verzeichnet werden, müssen in einer Setting-Datei verzeichnet werden, schon nur um sie von Relationen unterscheiden zu können.
Beispiel
Ein Dokument könnte nach diesem Schritt folgendermassen aussehen: